NPF驱动核心指南
[WinPcap 核心资料]
模块 | |
| NPF I/O 控制代码 | |
| NPF 结构与定义 | |
| NPF 函数 | |
| NPF 即时编译器定义 | |
详细描述
本节介绍网络组包过滤器(NPF),是 WinPcap 的核心。普通用户可能感兴趣的只是如何使用WinPcap的,而不是它的内部结构。因此,该模块中的内容主要面向 WinPcap 的开发者和维护者,或是对驱动程序的工作原理感兴趣的人。总体而言,具备良好的有关操作系统、网络、Win32内核编程以及设备驱动程序开发方面的知识将对阅读本章节很有帮助。
NPF 承担了 WinPcap 中的主要工作,为用户级提供了诸如数据包传输、捕获、注入和分析的能力。
下面的内容介绍了 NPF 与 OS 是如何交互的,以及 NPF 的基本结构。
NPF 和 NDIS
NDIS (网络驱动接口规范) 是一种标准,它定义了如何在网络适配器之间进行通信(或者说驱动如何管理通信)以及各种协议驱动(比如 TCP/IP 的实现)。NDIS 的主要目的让协议驱动能够在网络(LAN 或 WAN)上收发数据而忽略具体的网络适配器,特别是 Win32 操作系统。
NDIS 支持以下三种类型的网络驱动:
- 网络接口卡 或 NIC 驱动. NIC 驱动直接管理网络接口卡,简称 NIC。NIC 驱动往下可以直接访问硬件,往上向上层协议提供了诸如:发送数据包、处理中断、重置NIC、挂起NIC以及对各种操作特性的查询和设置功能。NIC驱动程序可以是微端口或传统全 NIC 驱动程序。
- 微端口驱动仅实现了管理NIC所必须的与硬件相关的操作,包括在NIC上收发数据。比如像同步这样的操作共同的最低级的NIC驱动,由 NDIS 提供。微端口不会直接调用操作系统提供的功能,而必须通过 NDIS 访问。
微端口并不会保存数据的信息,他仅是将数据包往上传给 NDIS,NDIS 将确保这些数据包被送往了正确的协议。 - 全 NIC 驱动则执行了通常由 NDIS 完成的硬件相关的操作和所有的同步以及查询操作。例如,全 NIC 驱动维护其自己的数据流信息用于指导数据接收。
- 微端口驱动仅实现了管理NIC所必须的与硬件相关的操作,包括在NIC上收发数据。比如像同步这样的操作共同的最低级的NIC驱动,由 NDIS 提供。微端口不会直接调用操作系统提供的功能,而必须通过 NDIS 访问。
- 中间层驱动. 中间驱动接口处于高层驱动比如协议驱动和微端口之间。对于高层驱动来说,中间层驱动看上去就像是微端口。对微端口来说,中间层就像是协议驱动。一个中间层协议驱动可以建在另外一个中间层驱动之上,尽管这样做可能会给系统性能带来一些负面效果。开发中间层的一个典型的原因是为了在一些现存的老式协议驱动和微端口之间提供媒介转换。例如:一个中间层驱动可以将 ATM 协议转化成 LAN 协议。 中间层协议不能与用户模式下的应用程序直接通信,而只能与其他 NDIS 驱动通信。
- 传输驱动或协议驱动. 协议驱动就是一种网络协议栈的实现,比如 IPX/SPX 或者 TCP/IP,为一个或者多个网络接口卡提供相关服务。协议驱动向上为应用层客户端提供服务,向下连接到一个或多个 NIC 驱动,或中间层 NDIS 驱动。
NPF 是被当作一种协议驱动来实现的。从性能角度看这也许不是最佳选择,但是允许合理的独立于MAC层以及对原始流量的完整访问。
注意,不同的 Win32 操作系统有不同版本的 NDIS:在 Windows2000 以及其同核心版本(比如 WinXP)下 NPF 与 NDIS 5 一致, 而在其他 Win32 平台下与 NDIS 3 一致。
下图展现了 NPF 在 NDIS 栈内的位置:
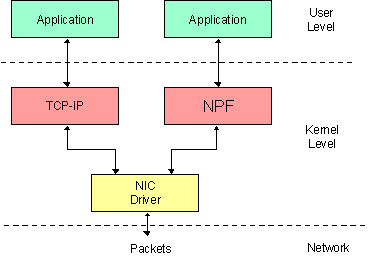
图 1: NDIS 内部的 NPF.
与操作系统的交互通常是异步进行的。这意味着驱动程序为系统提供了一套回调函数,当有请求 NPF 的操作时由系统调用。NPF 为所有应用的 I/O 操作提供回调函数:打开、关闭、读、写、IO控制等等。
与 NDIS 的交互也是异步的:比如当一个新数据包到达时,将通过一个回调函数(Packed_tap())通知 NPF。此外,NDIS 与 NIC 驱动之间的交互总是使用非阻塞函数:当 NPF 调用一个 NDIS 函数,该函数将立即返回;当处理结束后,NDIS 将调用一个指定的 NPF 回调函数去通知此函数的操作已经完成。驱动程序为任何低级操作都提供一个回调函数,比如在 NIC 上发送数据包,设定或者请求参数等等。
NPF 结构基础
下图展示了 WinPcap 的结构,特别对是 NPF 驱动
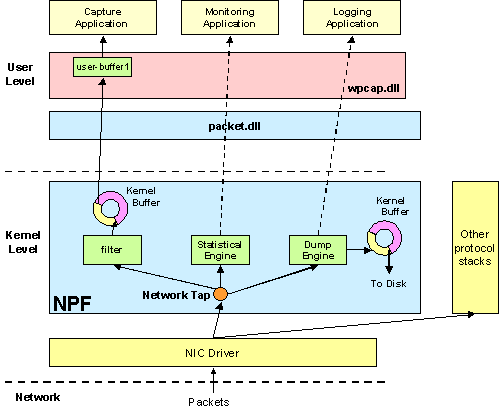
图 2: NPF 设备 驱动.
NPF 提供了不同的对数据包的操作:捕获、监控、转储、修改等等。后续内容将简要介绍这些操作。
数据包捕获
NPF 最重要的功能就是数据包捕获。驱动使用网络接口捕获一个数据包,并将其完好的投递给用户级应用程序。
捕获过程依赖两个主要组件:
当收到数据包的时候,由包过滤器决定是否接收这个数据包并且将其复制到正在等待的应用程序。大多数应用程序使用 NPF 拒绝的数据包比接收的多得多,因此一个多功能且高效率的包过滤器是得到好的整体性能的关键。包过滤器其实就是一个被应用到数据包上的带布尔输出的函数。如果函数返回值为真,捕获驱动将复制数据包到应用程序;如果为假数据包将会被丢弃。NPF 包过滤器要复杂一些,因为它不仅仅要决定数据包是否要被保存,还要考虑多少字节要被保存。被 NPF 所采用的过滤系统来自于BSD包过滤器(BPF),一个用伪汇编表示,并在用户级创建的可以用来执行过滤程序的虚拟处理器。应用程序使用 wpcap.dll 将用户定义的过滤器(比如:接收所有的 UDP 包)编译成一个 BPF 程序(比如:如果数据包是IP包,并且其 protocol type 等于 17,则返回真)。然后,应用程序使用 IOCTL BIOCSETF 将这个过滤器注入内核。这样这个程序就被应用在每一个收到的数据包上,并且只有符合条件的数据包才会被接受。有别于传统的解决方案, NPF 不会中断过滤器,只会执行其过滤规则。因为性能的原因,在使用过滤器之前,NPF 会将过滤器提交给一个 JIT 编译器将其转化成 原生的 80x86 函数。当一个数据包被捕获,NPF 将调用这个原生函数以替代调用过滤器的解释器,这将大大提高处理速度。这种优化处理背后的概念跟 Java jitters 非常相似
一个循环缓冲区来存储数据包,避免丢失。数据包被存储在缓冲区内并附带一个头部信息,包含了时间戳以及包大小的信息。另外在数据包之间会插入对齐填充数据以加快应用程序访问数据的速度。数据可以用一种单一的操作成组的从 NPF 的缓冲区复制到应用程序。降低读取数据的次数意味着性能的提高。如果在缓冲区已经满了的情况下还有新到的数据包,那么他们将会被丢弃。内核缓冲区和用户缓冲区都可以在运行时被改变,以提高灵活性:packet.dll 和 wpcap.dll 为实现这个目标提供了相关函数.
用户缓冲区的大小非常重要,因为它决定了单次系统调用中内能从内核复制最多数据到用户空间的能力。 而另一方面,单次系统调用中能处理的最小数据量同样也很重要。 当这个变量是一个比较大的值的时候,内核将等待多个数据包到达以后才会将他们复制到用户的应用程序。这将确保使用尽可能少的系统调用,即较低的处理器占用率,这对于像 Sniffers 这样的软件来说是比较好的设置。但是在另一方面,一个比较小的值则意味着内核将尽可能快速的复制数据包到已经准备好接收他们的应用程序。这对于需要从内核获得较好响应的实时应用来说是极好的(例如:ARP重定向或者桥接)。站在这个角度看, NPF 需要拥有可以进行配置的能力,允许用户去选择采用最佳性能或是最佳响应(或者任何介于性能和响应之间的情况)。
wpcap 库包含了一组系统调用可以用于设置读取超时时间以及最小数据传输量。默认读取数据超时时间为1秒,在内核与应用程序之间单次复制数据的最小数量是 16K。
数据包修改
NPF 允许在网络上写入原始数据。发送数据时,一个用户级应用程序在 NPF 设备文件上执行 WriteFile() 系统调用。然后原始数据将被发送到网络,而没有进行过任何协议封装,因此应用程序必须自己为每一个数据包构建各种包头。通常应用程序不需要提供 FCS,因为 FCS 是由网络适配器计算出来的,并在发送到网络之前自动附加到数据包的尾部。
正常情况下,发送数据包的速率并不是很高,因为每发送一个数据包都需要一次系统调用。 因为这个原因,单次写系统调用将能够尽可能多次发送单个数据包。用户级应用程序可以通过 IOCTL(代码 pBIOCSWRITEREP)设置单个数据包被重复发送的次数。例如:如果这个值被设置在 1000,那么每一个被应用程序写到驱动设备文件的原始数据包将被发送 1000 次。这个功能可以用来生成高速率的流量以用于某些测试的目的。
网络监控
WinPcap 提供了一个内核级别的可编程的监控模块,有能力对网络流量进行简单的数据统计。这个模块的中心思想展现在图2中:收集统计数据并不需要将数据包复制给应用程序,只需要简单展示从监控引擎获得的数据即可。这样可以避免对 CPU 和内存资源的大量消耗。
监控引擎是由一个带计数器的分类器构成。数据包将先由 NPF 的过滤引擎进行分类,并提供一个可配置的方法使其能够选择流量中的一个子集。数据通过过滤器以后将被送到计数器,计数器保存了多个变量,比如包的数量,总接收字节数等等,并且在有接收到新的数据包后更新这些变量。这些变量将在用户设定时隙内传给用户级应用程序。没有缓冲区分配在内核和用户级。
转储到磁盘
WinPcap 可以将网络数据从内核模式直接保存到磁盘。
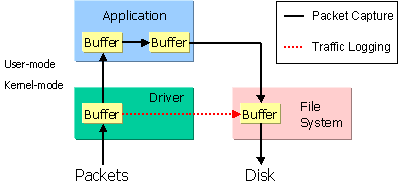
图 3: 数据包捕获 vs. 内核转储
在传统系统中,保存数据包到磁盘的路径由图3中黑色箭头表示,每一个数据包都将被复制几次,并且有4个缓冲区:一个用于捕获驱动,一个位于应用程序内部用于保存已经捕获的数据包,一个用于应用程序将数据包写到文件,最后一个属于文件系统。
当 NPF 中内核级流量记录功能被打开,捕获驱动将直接定位到文件系统,转储数据包到磁盘的路径见图中红色虚线箭头:这样只有两个缓冲区且只需要一次复制,因此系统调用的数量被大大降低,性能也就得到显著提升。
进一步阅读
NPF 的架构以及其过滤引擎均源自于 BSD 包过滤器(BPF),如果您对这个主题感兴趣,可以参考以下文献:
- S. McCanne and V. Jacobson, The BSD Packet Filter: A New Architecture for User-level Packet Capture. Proceedings of the 1993 Winter USENIX Technical Conference (San Diego, CA, Jan. 1993), USENIX.
- A. Begel, S. McCanne, S.L.Graham, BPF+: Exploiting Global Data-flow Optimization in a Generalized Packet Filter Architecture, Proceedings of ACM SIGCOMM '99, pages 123-134, Conference on Applications, technologies, architectures, and protocols for computer communications, August 30 - September 3, 1999, Cambridge, USA
注意
本手册中的代码主要基于 Windows NTx 的 NPF 版本。 基于 Win9x 的代码与此非常相似,但是效率较低,且缺少很多高级功能,比如内核转储。